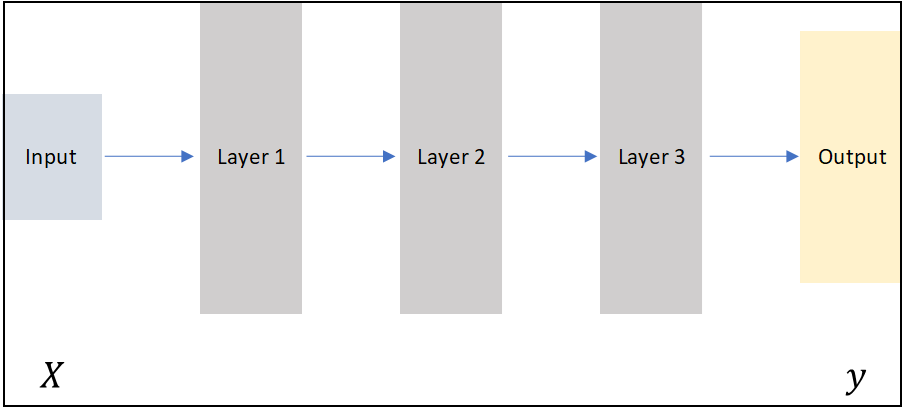
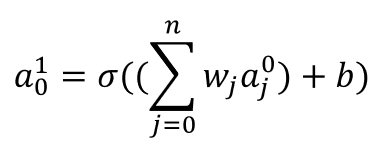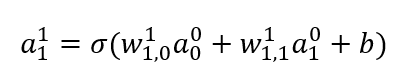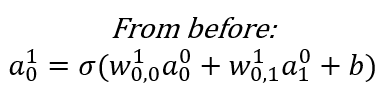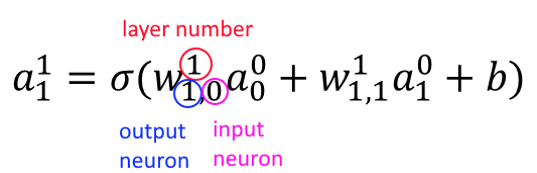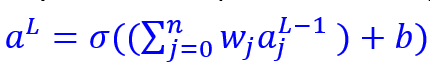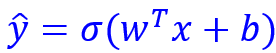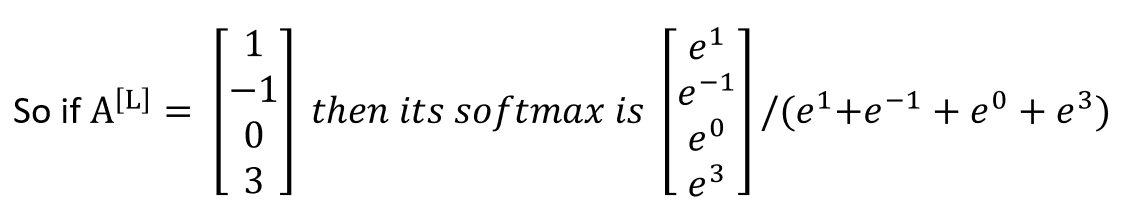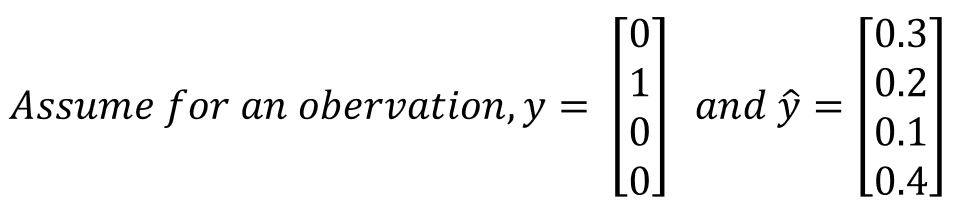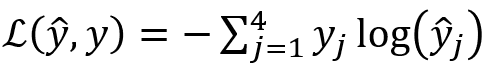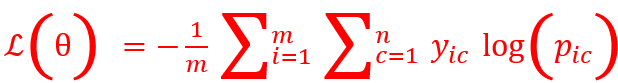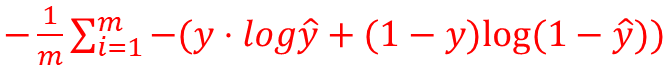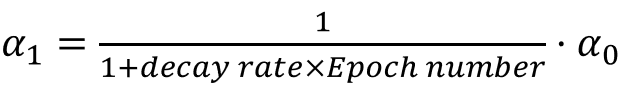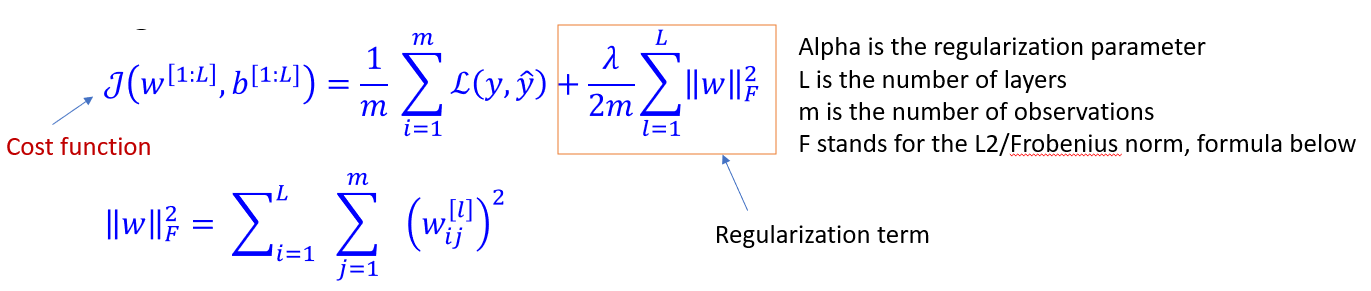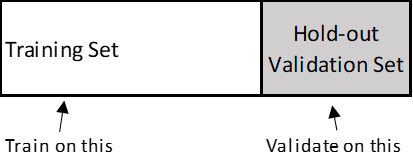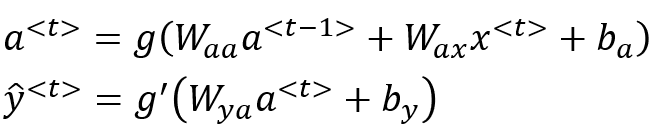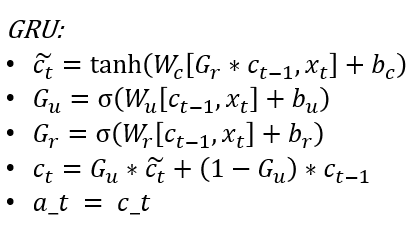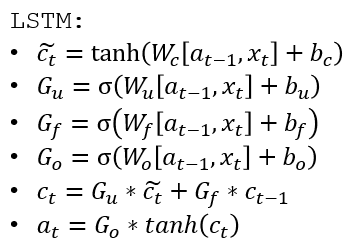Artificial Intelligence is the widest categorization of analytical methods that aim to automate intellectual tasks normally performed by humans. Machine learning can be considered to be a sub-set of the wider AI domain where a system is trained rather than explicitly programmed. It’s presented with many examples relevant to a task, and it finds statistical structure in these examples that eventually allows the system to come up with rules for automating the task.
The “deep” in deep learning is not a reference to any kind of deeper or intuitive understanding of data achieved by the approach. It simply stands for the idea of successive layers of representation of data. The number of layers in a model of the data is called the depth of the model.
image.png
Modern deep learning may involve tens or even hundreds of successive layers of representations. Each layer has parameters that have been ‘learned’ (or optimized) from the training data. These layered representations are encapsulated in models termed neural networks, quite literally layers of data arrays stacked on top of each other.
Deep Learning, ML and AI: Deep learning is a specific subfield of machine learning: learning from data that puts an emphasis on learning successive layers of increasingly meaningful representations. The deep in deep stands for this idea of successive layers of representations. Deep learning is used extensively for problems of perception – vision, speech and language.
image.png
The below graphic explains the difference between traditional programming and machine learning (which includes deep learning).
image.png
The transformer revolution (2017–present): The introduction of the Transformer architecture in 2017 (“Attention Is All You Need”) fundamentally changed the field. Today, BERT, GPT-4, and their descendants — built entirely on attention mechanisms — set the state of the art in language understanding, code generation, and reasoning. Vision Transformers (ViT) have similarly displaced CNNs at the top of image classification benchmarks. Multimodal models (CLIP, Gemini, GPT-4o) handle vision and language jointly.
PyTorch vs TensorFlow: PyTorch is now the dominant framework in research and has made major inroads in production. TensorFlow/Keras remains widely deployed, especially in mobile (TensorFlow Lite) and web (TensorFlow.js) contexts. The examples below use TensorFlow/Keras; the concepts — layers, activation functions, backpropagation — transfer directly to PyTorch.
18.2 A First Neural Net
Before we dive into more detail, let us build our first neural net with Tensorflow & Keras. This will help place in context the explanations that are provided later. Do not worry if not everything in the example makes sense yet, the goal is to get a high level view before we look at the more interesting stuff.
18.2.1 Diamond price prediction
We will use our diamonds dataset again, and try to predict the price of a diamond with the dataset. We load the data, and split it into training and test sets. In fact, we follow the regular machine learning workflow that we repeatedly followed in the prior chapter.
As always, some library imports first…
Code
import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersfrom tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Inputfrom tensorflow.keras import regularizersfrom tensorflow.keras.utils import to_categoricalimport numpy as npimport pandas as pdimport statsmodels.api as smimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn import datasetsfrom sklearn.metrics import mean_absolute_error, mean_squared_errorimport sklearn.preprocessing as preprocfrom sklearn.metrics import confusion_matrix, accuracy_score, classification_report, ConfusionMatrixDisplayfrom sklearn import metricsfrom sklearn.model_selection import train_test_split
## Get dummy variablesdiamonds = pd.get_dummies(diamonds, dtype=int) # pandas 2.0 default is bool; dtype=int keeps numeric downstream
Code
diamonds.head()
carat
depth
table
price
x
y
z
cut_Ideal
cut_Premium
cut_Very Good
...
color_I
color_J
clarity_IF
clarity_VVS1
clarity_VVS2
clarity_VS1
clarity_VS2
clarity_SI1
clarity_SI2
clarity_I1
0
0.23
61.5
55.0
326
3.95
3.98
2.43
True
False
False
...
False
False
False
False
False
False
False
False
True
False
1
0.21
59.8
61.0
326
3.89
3.84
2.31
False
True
False
...
False
False
False
False
False
False
False
True
False
False
2
0.23
56.9
65.0
327
4.05
4.07
2.31
False
False
False
...
False
False
False
False
False
True
False
False
False
False
3
0.29
62.4
58.0
334
4.20
4.23
2.63
False
True
False
...
True
False
False
False
False
False
True
False
False
False
4
0.31
63.3
58.0
335
4.34
4.35
2.75
False
False
False
...
False
True
False
False
False
False
False
False
True
False
5 rows × 27 columns
Code
## Define X and y as arrays. y is the price column, X is everything elseX = diamonds.loc[:, diamonds.columns !='price'].valuesy = diamonds.price.values
Code
## Train test splitfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size =0.20)# A step to convert the arrays to floatsX_train = X_train.astype('float')X_test = X_test.astype('float')
Next, we build a model
We created a model using Layers.
- A ‘Layer’ is a fundamental building block that takes an array, or a ‘tensor’ as an input, performs some calculations, and provides an output. Layers generally have weights, or parameters. Some layers are ‘stateless’, in that they do not have weights (eg, the flatten layer).
- Layers were arranged sequentially in our model. The output of a layer becomes the input for the next layer. Because layers will accept an input of only a certain shape, the layers need to be compatible.
- The arrangement of the layers defines the architecture of our model.
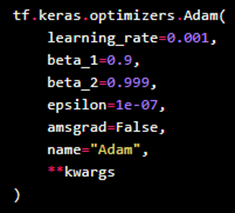
Compile the model.
Next, we compile() the model. The compile step configures the learning process. As part of this step, we define at least three more things: - The Loss function/Objective function,
- Optimizer, and
- Metrics.
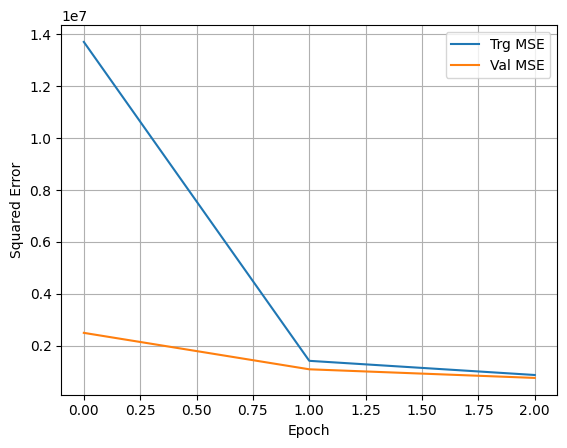
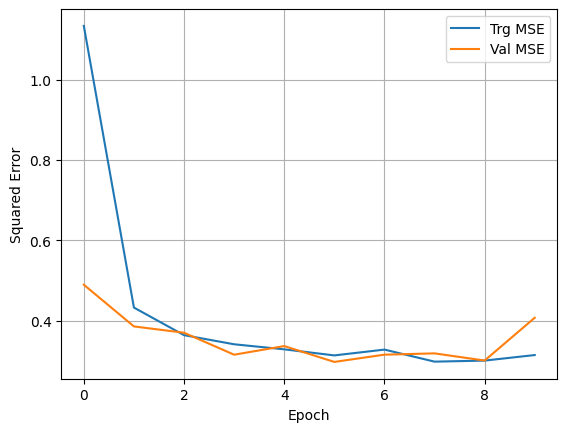
Notice that when fitting the model, we assigned the fitting process to a variable called history. This helps us capture the training metrics and plot them afterwards. We do that next.
## With the predictions in hand, we can calculate RMSE and other evaluation metricsprint('MSE = ', mean_squared_error(y_test,y_pred))print('RMSE = ', np.sqrt(mean_squared_error(y_test,y_pred)))print('MAE = ', mean_absolute_error(y_test,y_pred))
MSE = 1900421.5219580135
RMSE = 1378.5577688142102
MAE = 496.28198081792
Code
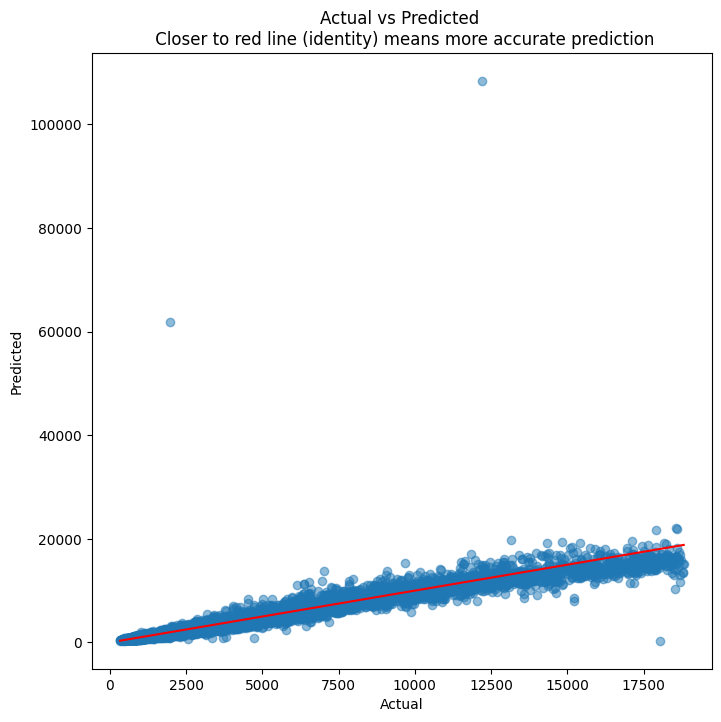
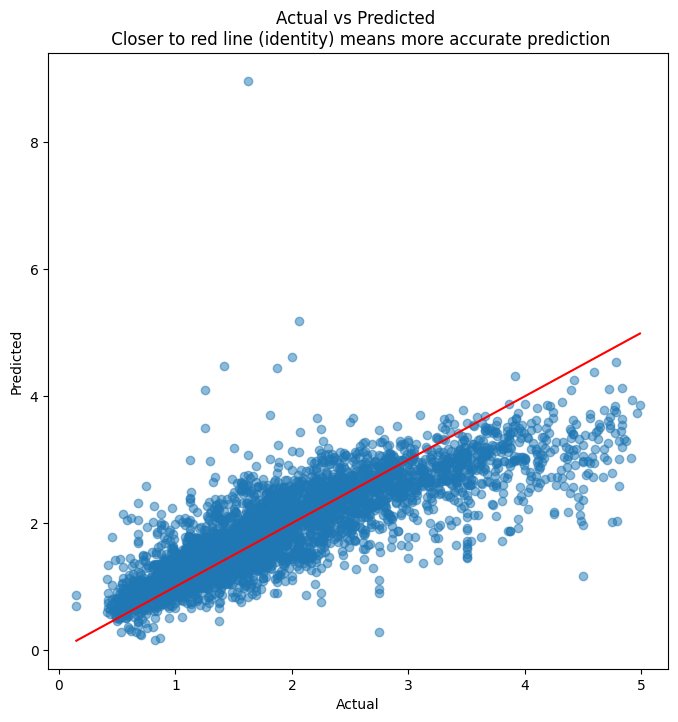
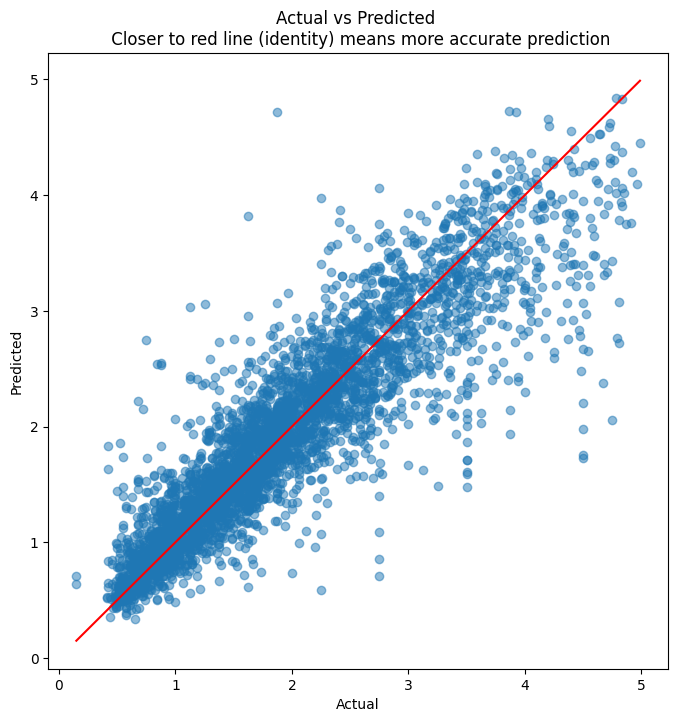
## Next, we scatterplot the actuals against the predictionsplt.figure(figsize = (8,8))plt.scatter(y_test, y_pred, alpha=0.5)plt.title('Actual vs Predicted \n Closer to red line (identity) means more accurate prediction')plt.plot( [y_test.min(),y_test.max()],[y_test.min(),y_test.max()], color='red' )plt.xlabel("Actual")plt.ylabel("Predicted")
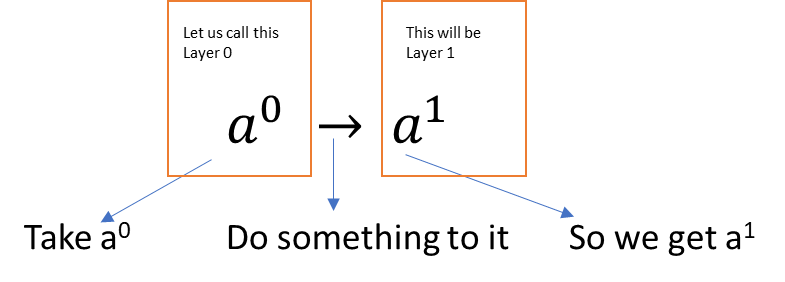
A neural net is akin to a mechanism that can model any type of function. So given any input, and a set of labels/outputs, we can ‘train the network’ to produce the output we desire.
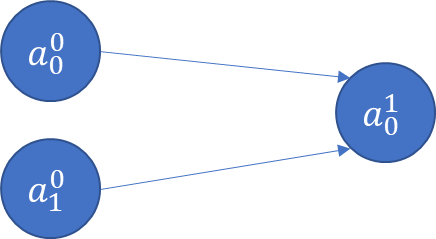
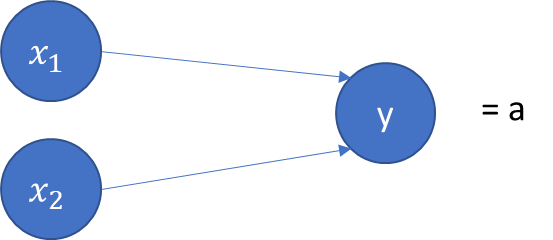
Imagine a simple case where there is an input \(a^0\) and an output \(a^1\). (The superscript indicates the layer number, and is not the same as a^n!)
image.png
In other words, we have a transformation to perform. One way to do this \(a^0→ a^1\) is using a scalar weight w, and a bias term b.
\(a^1=\sigma(wa^0+b)\)
- \(\sigma\) is the activation function (more on this later)
- w is the weight
- b is the bias
The question for us is: How can we derive the values of \(w\) and \(b\) as to get the correct value for the output?
Now imagine there are two input variables (or two features)
image.png
\(a_0^1=\sigma(w_0 a_0^0+w_1 a_1^0+b)\)
If we have more inputs/features, say \(a_j^0\), then generally:
image.png
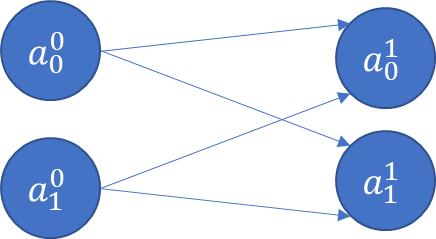
Now consider a situation where there is an extra output \(a_1^1\) (eg, multiple categories).
image.png
image.png
image.png
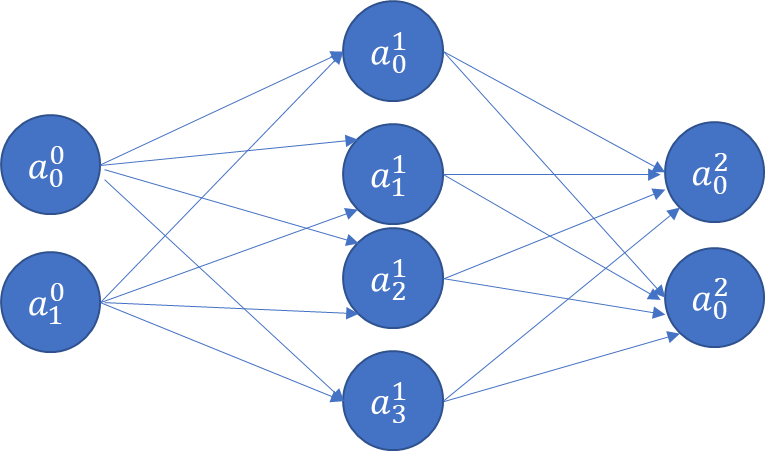
18.3.2 Hidden Layers
So far we have seen the input layer (called Layer 0), and the output layer (Layer 1). We started with one input, one output, and went to two inputs and two outputs.
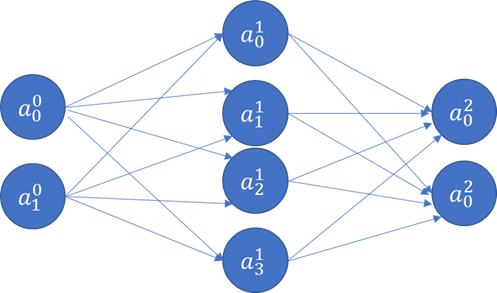
At this point, we have 4 weights, and 2 bias terms. We also don’t know what their values should be. Next, let us think about adding a new hidden layer between the input and the output layers!
image.png
The above is a fully connected network, because each node is connected with every node in the subsequent layer. ‘Connected’ means the node contributes to the calculation of the subsequent node in the network.
The value of each node (other than the input layer which is provided to us) can be calculated by a generalization of the formula below. Fortunately, all the weights for a Layer can be captured as a weights matrix, and all the biases can also be captured as a vector. That makes the math expression very concise.
image.png
An Example Calculation
Generalizing the Calculation
In fact, not only can we combine all the weights and bias for a single layer into a convenient matrix representation, we can also combine all the weights and biases for all the layers in a network into a single weights matrix, and a bias matrix.
The arrangement of the weights and biases matrices, that is, the manner in which the dimensions are chosen, and the weights/biases are recorded inside the matrix, is done in a way that they can simply be multiplied to get the final results.
This reduces the representation of the network’s equation to: \(\hat{y}=\sigma(w^T x+b)\), where w is the weights matrix, b is the bias matrix, and is the activation function. (y-hat is the prediction, and \(w^T\) stands for transpose of the weights matrix. The transposition is generally required given the traditional way of writing the weights matrix.)
image.png
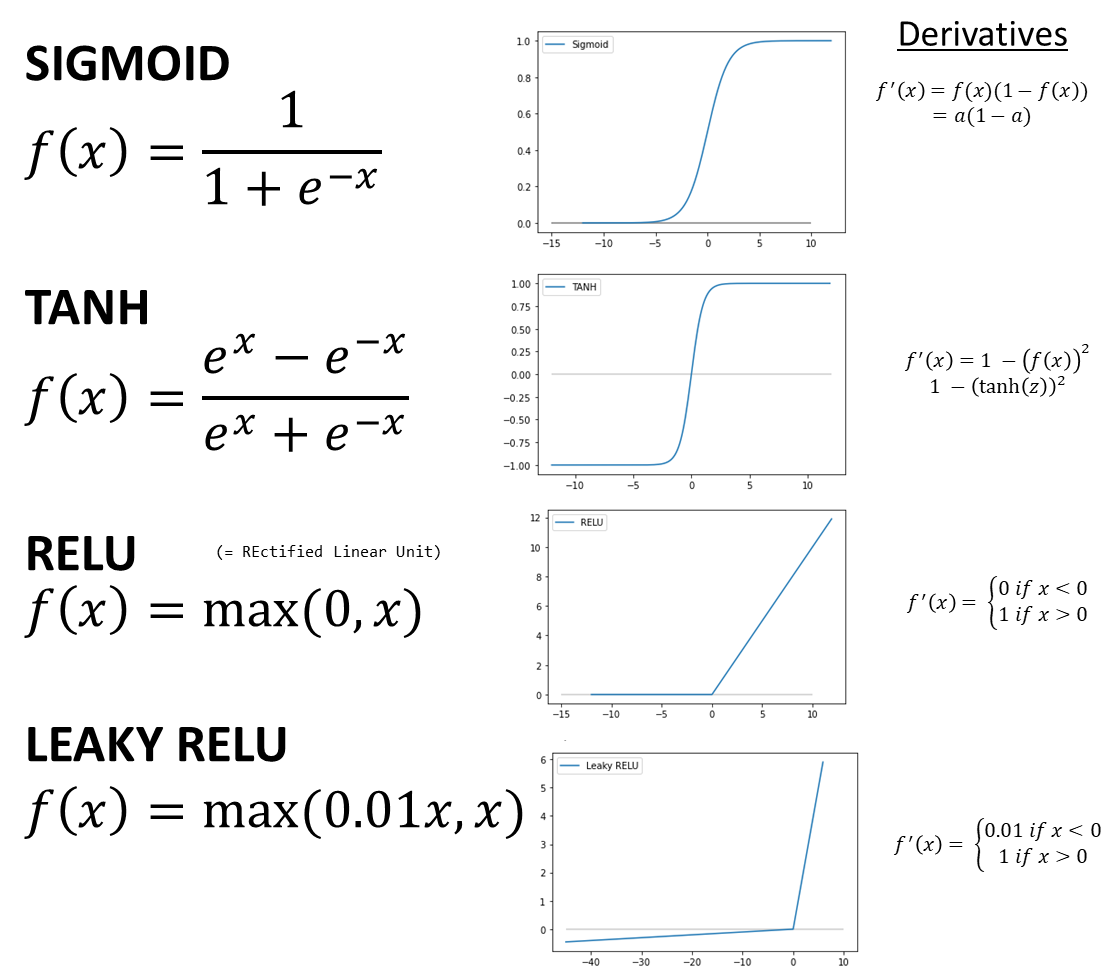
18.3.3 Activation Function
So far all we have covered is that in a neural net, every subsequent layer is a function of weights, bias, and something that is called an activation function.
Before the function is applied, the math is linear, and the equation similar to the one for regression (compare \(mx+b\) to \(w^T x+b\)).
An activation function is applied to the linear output of a layer to obtain a non-linear output. The ability to obtain non-linear results significantly expands the nature of problems that can be solved, as decision boundaries of any shape can be modeled. There are many different choices of activation functions, and a choice is generally made based on the use case.
The below are the most commonly used activation functions.
You can find many other specialized activation functions in other textbooks, and also on Wikipedia.
The main function of activation functions is to allow non-linearity into the outputs, increasing significantly the flexibility of the patterns that can be modeled by a neural network.
image.png
18.3.3.1 Softmax Activation
The softmax activation takes a vector and raises \(e\) to the power of each of its elements. This has the effect of making everything a positive number.
If we want probabilities, then we can divide each of the elements by the sum of the elements, ie by dividing the softmax by \((e^1 + e^{-1} + e^0 + e^3)\).
image.png
A vector obtained from a softmax operations will have probabilities that add to 1.
A HARDMAX will be identical to a softmax except that all entries will be zero except one which will be equal to 1.
Loss Calculation for Softmax
image.png
In this case, the loss for the above will be calculated as:
image.png
Here you have only the second category, ie \(y_2=1\), the rest are zero.
So effectively the loss reduces to \(-log(0.2)\).
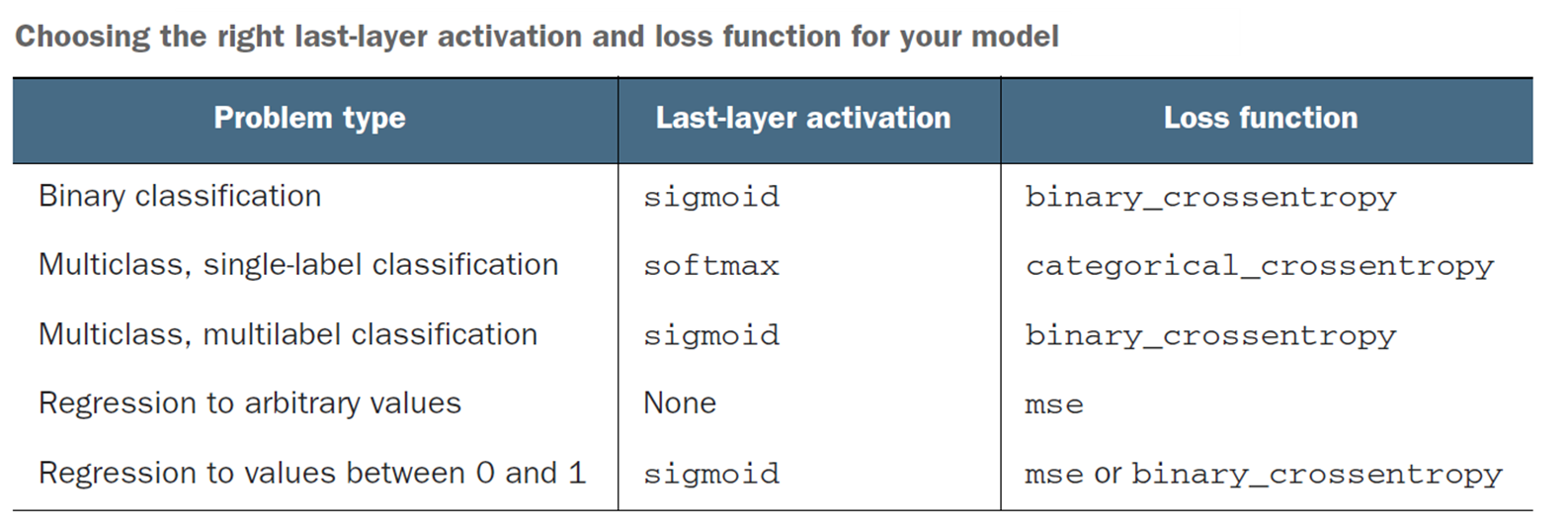
18.3.4 Which Activation Function to Use?
Mostly always RELU for hidden layers.
The last layer’s activation function must match your use case, and give you an answer in the shape you desire your output. So SIGMOID would not be a useful activation function for a regression problem (eg, home prices).
image.png
Source: Deep Learning with Python, François Chollet, Manning Publications
GELU (Gaussian Error Linear Unit): Transformers (BERT, GPT) predominantly use GELU rather than ReLU for hidden layers. GELU is a smooth approximation to ReLU that tends to train better on language tasks. For most vision and tabular tasks, ReLU or LeakyReLU remains the default choice. In Keras: activation='gelu'.
18.3.5 Compiling a Model
Compiling a model means configures it for training. As part of compiling the model, you specify the loss function, the metrics and the optimizer to use. These are provided as three parameters: - Optimizer: Use rmsprop, and leave the default learning rate. (You can also try adam if rmsprop errors out.) - Loss: Generally mse for regression problems, and binary_crossentropy/ categorical_crossentropy for binary and multiclass classification problems respectively.
- Categorical Cross Entropy loss is given by
where i=1 to m are m observations, c= 1 to n are n classes, and \(p_{ic}\) is the predicted probability.
If you have only two classes, ie binary classification, you get the loss
image.png
Metrics: This can be accuracy for classification, and MAE or MSE for regression problems.
The difference between Metrics and Loss is that metrics are for humans to interpret, and need to be intuitive. Loss functions may use similar measures that are mathematically elegant, eg differentiable, continuous etc. Often they can be the same (eg MSE), but sometimes they can be different (eg, cross entropy for classification, but accuracy for humans).
18.3.6 Backpropagation
How do we get w and b?
So far, we have understood how a neural net is constructed, but how do we get the values of weights and biases so that the final layer gives us our desired output?
At this point, calculus comes to our rescue.
If y is our label/target, we want y-hat to be the same as (or as close as possible) to y.
The loss function that we seek to minimize is a function of \(L(\hat{y},y)\), where $ $ is our prediction of \(y\), and \(y\) is the true value/label. Know that $ $ is also known as \(a\), using the convention for nodes.
The Setup for Understanding Backprop
Let us consider a simple example of binary classification, with two features x_1 and x_2 in our feature vector X. There are two weights, w_1 and w_2, and a bias term b. Our output is a. In other words:
image.png
Our goal is to calculate a, or
\(\hat{y}=a=\sigma(z)\), where \(z=w_1 x_1+w_2 x_2+b\)
We use the sigmoid function as our activation function, and use the log-loss as our Loss function to optimize.
Loss Function: \(L(\hat{y},y)= −(y\cdotlog\hat{y}+(1−y)log(1−\hat{y})\))
We need to minimize the loss function. We can minimize a function by calculating its derivative (and setting it equal to zero, etc)
Our loss function is a function of \(w_1,w_2\) and \(b\). (Look again at the equations on the prior slide to confirm.)
If we can calculate the partial derivatives \(\delta L/\delta w_1\),\(\delta L/\delta w_2\) and \(\delta L/\delta b\) (or the Jacobian vector of partial derivatives), we can get to the minimum for our Loss function.
For the loss function for our example, the derivative of the log-loss function is \(f'(x) = f(x)(1-f(x)) = a(1-a)\) (stated without proof, but can be easily derived using the chain rule).
That is an elegant derivative, easily computed. Since backpropagation uses the chain rule for derivatives, which ends up pulling in the activation function into the mix together with the loss function, it is important that activation functions be differentiable.
How it works
1. We start with random values for \(w_1\),\(w_2\) and \(b\).
2. We figure out the formulas for \(\delta L/\delta w_1\),\(\delta L/\delta w_2\) and \(\delta L/\delta b\).
3. For each observation in our training set, we calculate the value of the derivative for each \(x_1\),\(x_2\) etc.
4. We average the derivatives for the observations to get the derivative for our entire training population.
5. We use this average derivative value to get the next better value of \(w_1\),\(w_2\) and \(b\).
- \(w_1 :=w_1−\alpha \delta L/(\delta w_1 )\)
- \(w_2 :=w_2−\alpha \delta L/(\delta w_2 )\)
- \(b :=b−\alpha \delta L/\delta b\)
6. Where $$ is the learning rate as we don’t want to go too fast and miss the minima.
7. Once we have better values of \(w_1\),\(w_2\) and \(b\), we repeat this again.
image.png
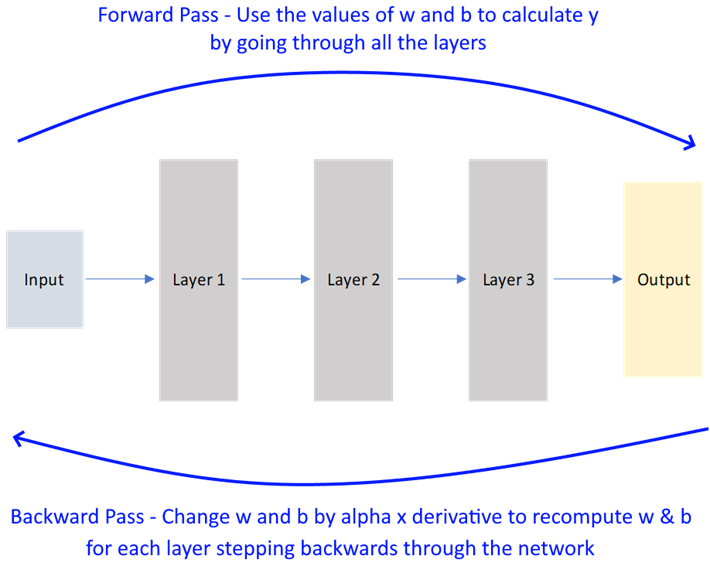
Backpropagation
Perform iterations – a full forward pass followed by a backward pass is a single iteration.
For every iteration, you can use all the observations, or only a sample to speed up learning. The number of observations in an iteration is called batch size.
When all observations have completed an iteration, an epoch is said to have been completed.
That, in short, is how back-propagation works. Because it uses derivatives to arrive at the optimum value, it is also called gradient descent.
image.png
We considered a very simple two variable case, but even with larger networks and thousands of variables, the concept is the same.
18.3.7 Batch Sizes & Epochs
BATCH GRADIENT DESCENT
If you have m examples and pass all of them through the forward and backward pass simultaneously, it would be called BATCH GRADIENT DESCENT.
If m is very large, say 5 million observations, then the gradient descent process can become very slow.
MINI-BATCH GRADIENT DESCENT
A better strategy may be to divide the m observations into mini-batches of 1000 each so that we can start getting the benefit from gradient descent quickly. So we can divide m into ‘t’ mini-batches and loop through the t batches one by one, and keep improving network performance with each mini-batch. Mini batch sizes are generally powers of 2, eg 64 (2^6), 128, 256, 512, 1024 etc. So if m is 5 million, and mini-batch size is 1000, t will be from 1 to 5000.
STOCHASTIC GRADIENT DESCENT
When mini-batch size is 1, it is called stochastic gradient descent, or SGD.
To sum up:
- When mini batch size = m, it is called BATCH GRADIENT DESCENT.
- When mini batch size = 1, it is called STOCHASTIC GRADIENT DESCENT.
- When mini batch size is between 1 and m, it is called MINI-BATCH GRADIENT DESCENT.
What is an EPOCH
An epoch is when the entire training dataset has been worked through the backpropagation algorithm. That is when a complete pass of the data has been completed through the backpropagation algorithm.
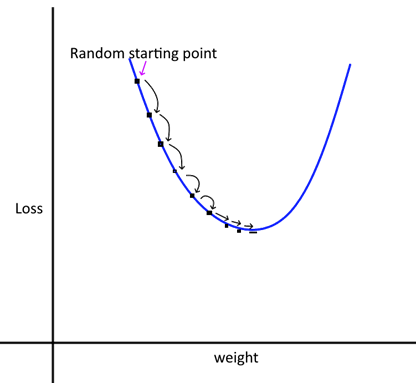
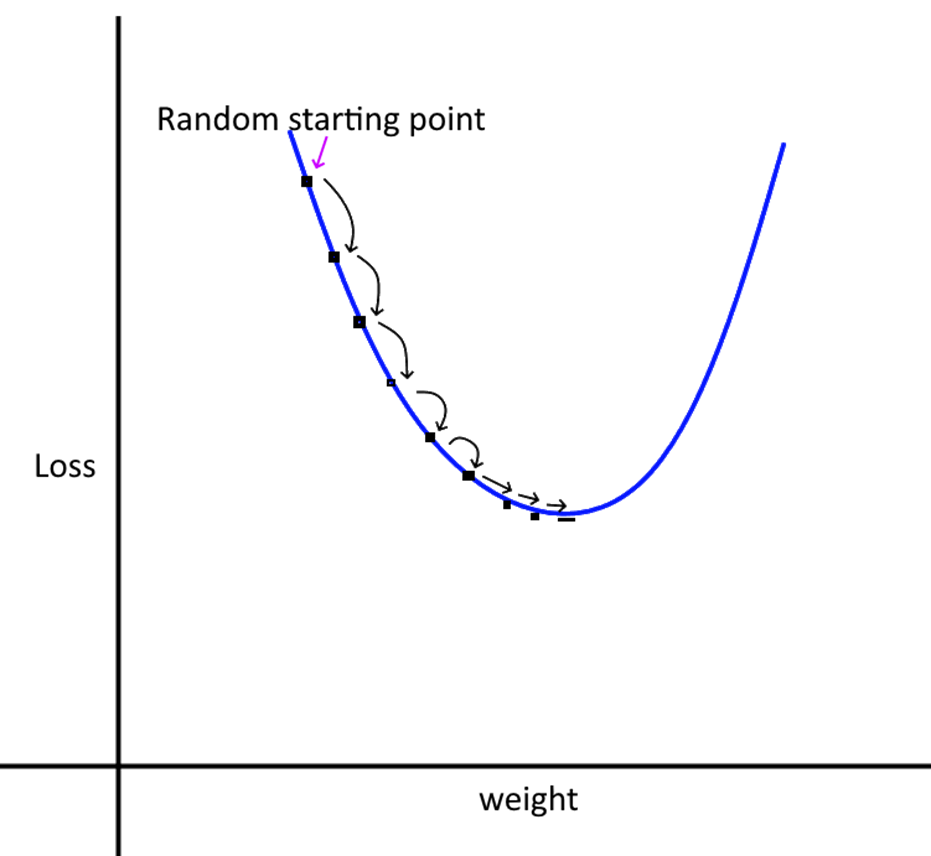
18.3.8 Learning Rate
We take small steps from our random starting point to the optimum value of the weights and biases. The step size is controlled by the learning rate (alpha). If the learning rate is too small, it will take very long for the training to complete. If the rate is large, we may miss the minima as we may step over it.
image.png
Intuitively, what we want is large steps in the beginning, and slower steps as we get closer to the optimal point.
We can do this by using a momentum term, which can make the move towards the op+timum faster.
The momentum term is called \(\beta\) beta, and it is in addition to the term.
There are several optimization algorithms to choose from (eg ADAM, RMS Prop), and each may have its own implementation of beta.
We can also vary the learning rate by decaying it for each subsequent epoch, for example:
Consider the network in the image. Each node’s output is \(a^L\), and represents a ‘feature’ for consumption by the next layer.
This feature is a new feature calculated as a synthetic combination of previous inputs using \(\sigma(w^T x+b)\).
Each layer will have a weights vector \(w^L\), and a bias \(b^L\).
Let us pause a moment to think about how many weights and biases we need, and generally the ‘shape’ of our network.
Layer 0 is the input layer. It will have m observations and n features.
In the example network below, there are 2 features in our input layer.
The 2 features join with 4 nodes in Layer 1. For each node in Layer 1, we need 2 weights and 1 bias term. Since there are 4 nodes in Layer 2, we will need 8 weights and 4 biases.
For the output layer, each of the 2 nodes will have 4 weights, and 1 bias term, making for 8 weights and 2 bias parameters.
For the entire network, we need to optimize 16 weights and 6 bias parameters. And this has to be done for every single observation in the training set for each epoch.
18.3.9.2 Hyperparameters
Hyperparameters for a network control several architectural aspects of a network. The below are the key hyperparameters an analyst needs to think about: - Learning rate (alpha)
- Mini-batch size
- Beta (momentum term)
- Number of hidden neurons in each layer
- Number of layers
There are other hyperparameters as well, and different hyperparameters for different network architectures.
All hyperparameters can be specified as part of the deep learning network.
image.png
Applied deep learning is a very empirical process, ie, requires a lot of trial and error.
18.3.10 Overfitting
The Problem of Overfitting
Optimization refers to the process of adjusting a model to get the best performance on training data.
Generalization refers to how well the model performs on data it has not seen before.
As part of optimization, the model will try to “memorize” the training data using the parameters it is allowed. If there is not a lot of data to train on, optimization may happen quickly, as patterns would be learned.
But such a model may have poor real world performance, while having exceptional training set performance. This problem is called ‘overfitting’.
Fighting Overfitting
There are several ways of dealing with overfitting:
- Get more training data: More training data means better generalization, and avoiding learning misleading patterns that only exist in the training data.
- Reduce the size of the network: By reducing layers and nodes in the network, we can reduce the ability of the network to overfit. Surprisingly, smaller networks can have better results than larger ones!
- Regularization: Penalize large weights, biases and activations.
Regularization of Networks
#### L2 Regularization - In regularization, we add a term to our cost function as to create a penalty for large w vectors. This helps reduce variance (overfitting) by pushing w entries closer to zero. - But regularization can increase bias, but often a balance can be struck. - L2 regularization can cause ‘weight decay’, ie gradient descent shrinks the weights on each iteration.
image.png
In Keras, regularization can be specified as part of the layer parameters.
image.png
Source: https://keras.io/api/layers/regularizers/
18.3.10.1 Drop-out Regularization
With drop-out regularization, we drop, which means completely zero out many of a network’s nodes by setting their output to zero. We do this separately for each observation in the forward prop step. Which means in the same pass, different nodes would be deleted for each training example. This has the effect of reducing network size, hence reducing variance/overfitting.
Setting a node’s output to zero means eliminating an input into the next layer. Which means reducing features at random. Since inputs disappear at random, the weight gets spread out instead of relying upon one feature.
‘Keep-prob’ means how much of the network we keep. So 80% keep-prob means we drop 20%. You can have different keep-prob values for different layers.
One disadvantage of drop-out regularization is that the cost function becomes ill defined. And gradient descent does not work well.
So you can still optimize without drop-outs, and once all hyper-parameters have been optimized, switch to a drop-out version with the hope that the same hyper-parameters are still the best.
Drop-out regularization is implemented in Keras as a layer type.
18.3.11 Training, Validation and Test Sets
In deep learning, data is split into 3 sets: training, validation and test.
- Train on training data, and evaluate on validation data.
- When ready for the real world, test it a final time on the test set
Why not just training and test sets? This is because developing a model always involves tuning its hyperparameters. This tuning happens on the validation set.
Doing it repeatedly can lead to overfitting to the validation set, even though the model never directly sees it. As you tweak the hyperparameters repeatedly, information leakage occurs where the algorithm starts to fit the model to do well on the validation set, with poor generalization.
Approaches to Validation
Two primary approaches:
- Simple hold-out validation: Useful if you have lots of data
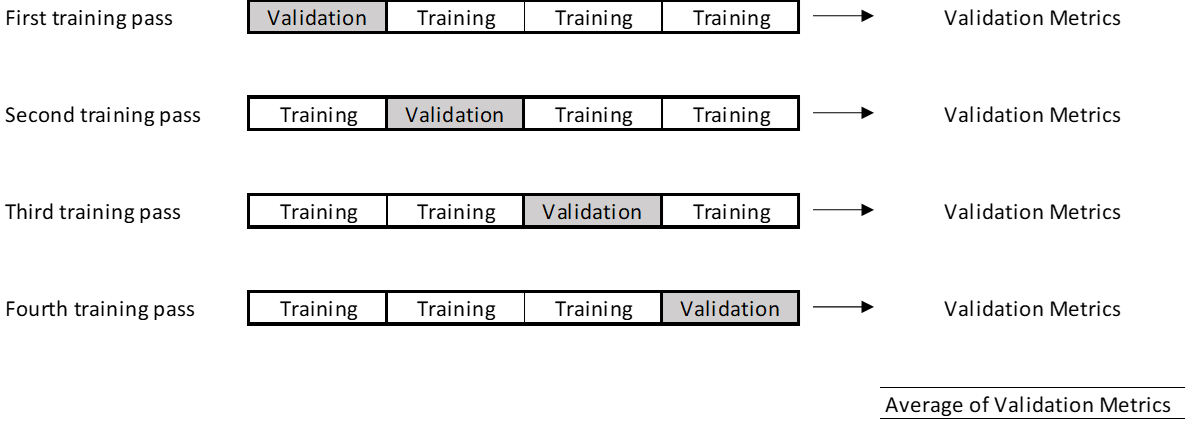
- K-fold Validation: (in the illustration below, k is 4) – if you have less data
image.png
18.3.12 Data Pre-Processing for Neural Nets
All data must be expressed as tensors (another name for arrays) of floating point data. Not integers, not text. Neural networks: - Do not like large numbers. Ideally, your data should be in the 0-1 range.
- Do not like heterogenous data. Data is heterogenous when one feature is in the range, say, 0-1, and another is in the range 0-100.
The above upset gradient updates, and the network may not converge or give you good results. Standard Scaling of the data can help avoid the above problems. As a default option – always standard scale your data.
18.4 Examples
18.5 California Housing - Deep Learning
Next, we try to predict home prices using the California Housing dataset
Code
## California housing dataset. medv is the median value to predictfrom sklearn import datasetsX = datasets.fetch_california_housing()['data']y = datasets.fetch_california_housing()['target']features = datasets.fetch_california_housing()['feature_names']DESCR = datasets.fetch_california_housing()['DESCR']cali_df = pd.DataFrame(X, columns = features)cali_df.insert(0,'Value', y)cali_df
Value
MedInc
HouseAge
AveRooms
AveBedrms
Population
AveOccup
Latitude
Longitude
0
4.526
8.3252
41.0
6.984127
1.023810
322.0
2.555556
37.88
-122.23
1
3.585
8.3014
21.0
6.238137
0.971880
2401.0
2.109842
37.86
-122.22
2
3.521
7.2574
52.0
8.288136
1.073446
496.0
2.802260
37.85
-122.24
3
3.413
5.6431
52.0
5.817352
1.073059
558.0
2.547945
37.85
-122.25
4
3.422
3.8462
52.0
6.281853
1.081081
565.0
2.181467
37.85
-122.25
...
...
...
...
...
...
...
...
...
...
20635
0.781
1.5603
25.0
5.045455
1.133333
845.0
2.560606
39.48
-121.09
20636
0.771
2.5568
18.0
6.114035
1.315789
356.0
3.122807
39.49
-121.21
20637
0.923
1.7000
17.0
5.205543
1.120092
1007.0
2.325635
39.43
-121.22
20638
0.847
1.8672
18.0
5.329513
1.171920
741.0
2.123209
39.43
-121.32
20639
0.894
2.3886
16.0
5.254717
1.162264
1387.0
2.616981
39.37
-121.24
20640 rows × 9 columns
Code
cali_df.Value.describe()
count 20640.000000
mean 2.068558
std 1.153956
min 0.149990
25% 1.196000
50% 1.797000
75% 2.647250
max 5.000010
Name: Value, dtype: float64
Code
cali_df = cali_df.query("Value<5")
Code
X = cali_df.iloc[:, 1:]y = cali_df.iloc[:, :1]
Code
X = pd.DataFrame(preproc.StandardScaler().fit_transform(X))X_train, X_test, y_train, y_test = train_test_split(X, y, test_size =0.20)
MSE = 0.3026244068858136
RMSE = 0.5501130855431577
MAE = 0.38099100065650404
Code
plt.figure(figsize = (8,8))plt.scatter(y_test, y_pred, alpha=0.5)plt.title('Actual vs Predicted \n Closer to red line (identity) means more accurate prediction')plt.plot( [y_test.min(),y_test.max()],[y_test.min(),y_test.max()], color='red' )plt.xlabel("Actual")plt.ylabel("Predicted")
MSE = 0.18330689553497856
RMSE = 0.4281435454785913
MAE = 0.28907724570828114
Code
## Evaluate residualsplt.figure(figsize = (8,8))plt.scatter(y_test, y_pred, alpha=0.5)plt.title('Actual vs Predicted \n Closer to red line (identity) means more accurate prediction')plt.plot( [y_test.min(),y_test.max()],[y_test.min(),y_test.max()], color='red' )plt.xlabel("Actual")plt.ylabel("Predicted");
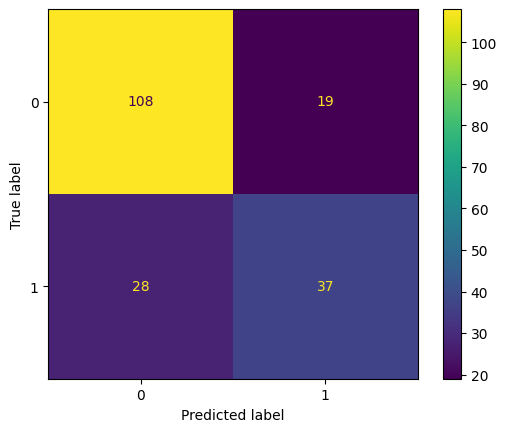
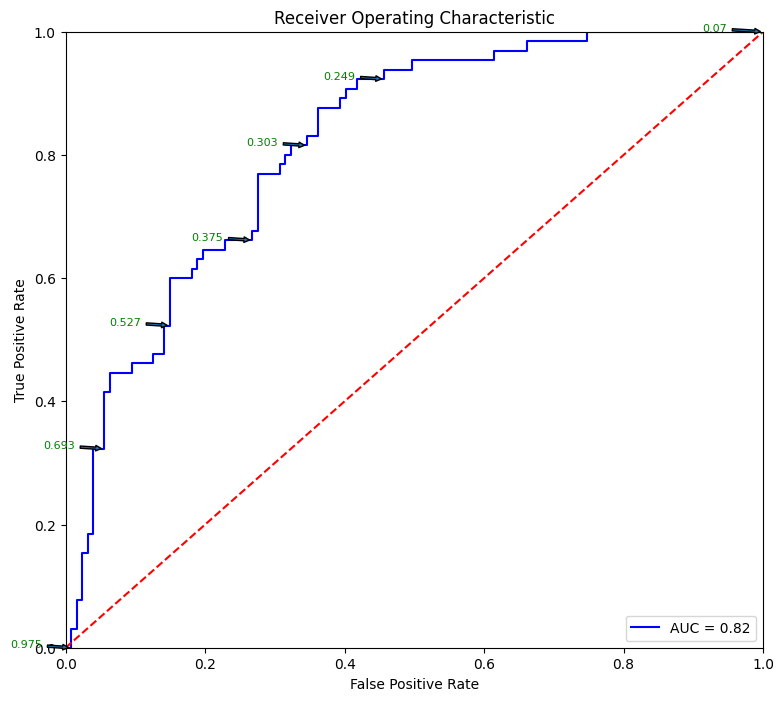
# Source for code below: https://stackoverflow.com/questions/25009284/how-to-plot-roc-curve-in-pythonfpr, tpr, thresholds = metrics.roc_curve(y_test, pred_prob)roc_auc = metrics.auc(fpr, tpr)plt.figure(figsize = (9,8))plt.title('Receiver Operating Characteristic')plt.plot(fpr, tpr, 'b', label ='AUC = %0.2f'% roc_auc)plt.legend(loc ='lower right')plt.plot([0, 1], [0, 1],'r--')plt.xlim([0, 1])plt.ylim([0, 1])plt.ylabel('True Positive Rate')plt.xlabel('False Positive Rate')for i, txt inenumerate(thresholds):if i in np.arange(1, len(thresholds), 10): # print every 10th point to prevent overplotting: plt.annotate(text =round(txt,3), xy = (fpr[i], tpr[i]), xytext=(-44, 0), textcoords='offset points', arrowprops={'arrowstyle':"simple"}, color='green',fontsize=8)plt.show()
18.7 Multi-class Classification Example
Code
df=sns.load_dataset('iris')
Code
df
sepal_length
sepal_width
petal_length
petal_width
species
0
5.1
3.5
1.4
0.2
setosa
1
4.9
3.0
1.4
0.2
setosa
2
4.7
3.2
1.3
0.2
setosa
3
4.6
3.1
1.5
0.2
setosa
4
5.0
3.6
1.4
0.2
setosa
...
...
...
...
...
...
145
6.7
3.0
5.2
2.3
virginica
146
6.3
2.5
5.0
1.9
virginica
147
6.5
3.0
5.2
2.0
virginica
148
6.2
3.4
5.4
2.3
virginica
149
5.9
3.0
5.1
1.8
virginica
150 rows × 5 columns
Code
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()encoded_labels = le.fit_transform(df['species'].values.ravel()) ## This needs a 1D arrarylist(enumerate(le.classes_))
from tensorflow.keras.utils import to_categoricalX = df.iloc[:,:4]y = to_categorical(encoded_labels)
Code
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Code
model = keras.Sequential()model.add(Dense(12, input_dim=X_train.shape[1], activation='relu'))model.add(Dense(8, activation='relu'))model.add(Dense(3, activation='softmax'))## compile the keras modelmodel.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])## fit the keras model on the datasetcallback = tf.keras.callbacks.EarlyStopping(monitor='accuracy', patience=4)model.fit(X_train, y_train, epochs=150, batch_size=10, callbacks = [callback])print('\nDone')
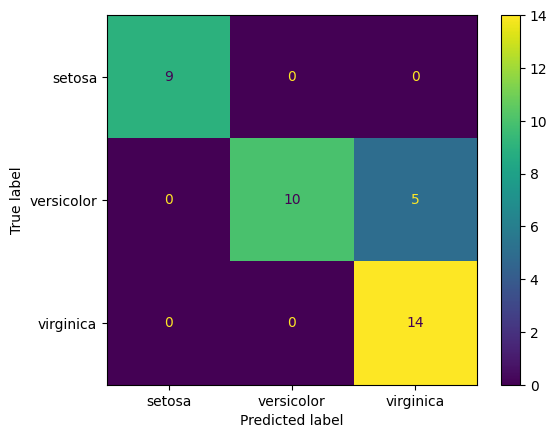
ConfusionMatrixDisplay.from_predictions([np.argmax(x) for x in y_test], [np.argmax(x) for x in pred], display_labels=le.classes_)
18.8 Image Recognition with CNNs
CNNs are used for image related predictions and analytics. Uses include image classification, image detection (identify multiple objects in an image), classification with localization (draw a bounding box around an object of interest).
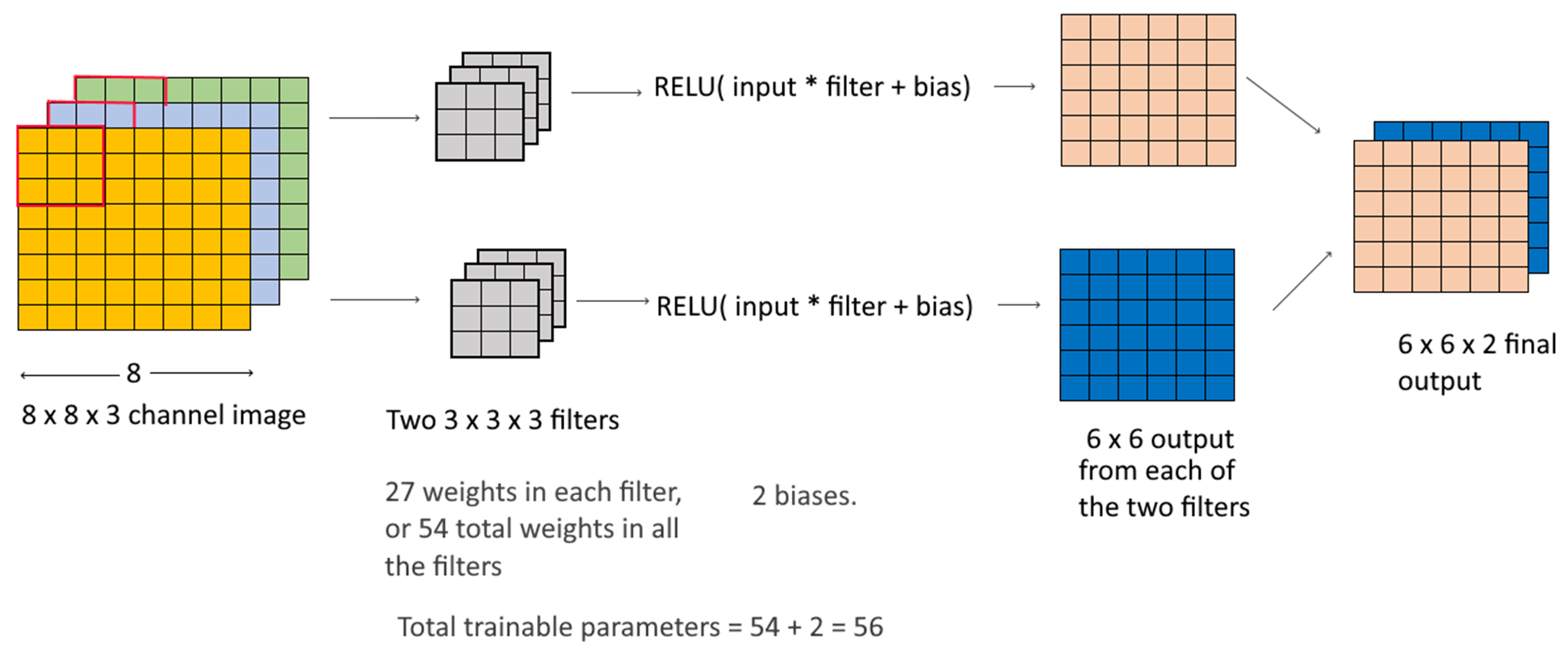
CNNs also use weights and biases, but the approach and calculations are different from those done in a dense layer. A convolutional layer applies to images, which are 3-dimensional arrays – height, width and channel. Color images have 3 channels (one for each color RGB), while greyscale images have only 1 channel.
Consider a 3 x 3 filter applied to a 3-channel 8 x 8 image:
image.png
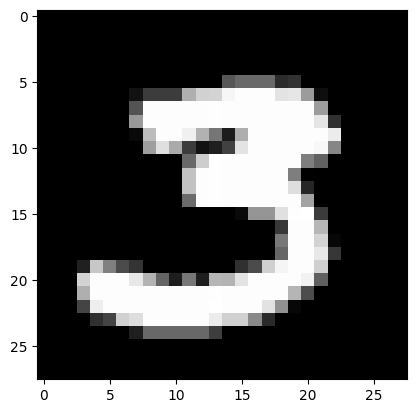
We classify the MNIST dataset, which is built-in into keras. This is a set of 60,000 training images, plus 10,000 test images, assembled by the National Institute of Standards and Technology (the NIST in MNIST) in the 1980s.
Modeling the MNIST image dataset is akin to the ‘Hello World’ of image based deep learning. Every image is a 28 x 28 array, with numbers between 1 and 255 (\(2^8\))
Example images:
image.png
Vision Transformers (ViT): Since 2020, Vision Transformers have challenged CNN dominance on image benchmarks. Instead of convolutional filters, ViT splits an image into fixed-size patches and processes them as a sequence using self-attention — the same mechanism as BERT. For production image tasks, pre-trained ViT models from Hugging Face (google/vit-base-patch16-224) fine-tuned on your data now often outperform custom CNNs without any architectural design effort.
Next, we will try to build a network to identify the digits in the MNIST dataset
Code
from tensorflow.keras.datasets import mnist(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
## We reshape the image arrays in a form that can be fed to the CNNtrain_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype("float32") /255test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype("float32") /255
Code
from tensorflow import kerasfrom tensorflow.keras.layers import Flatten, MaxPooling2D, Conv2D, Inputmodel = keras.Sequential()model.add(Input(shape=(28, 28, 1)))model.add(Conv2D(filters=32, kernel_size=3, activation="relu"))model.add(MaxPooling2D(pool_size=2))model.add(Conv2D(filters=64, kernel_size=3, activation="relu"))model.add(MaxPooling2D(pool_size=2))model.add(Conv2D(filters=128, kernel_size=3, activation="relu"))model.add(Flatten())model.add(Dense(10, activation='softmax'))## compile the keras modelmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
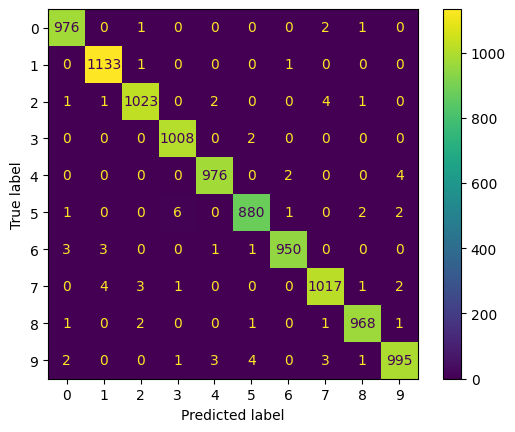
ConfusionMatrixDisplay.from_predictions(test_labels, [np.argmax(x) for x in pred])
18.9 Recurrent Neural Networks
One issue with Dense layers is they have no ‘memory’. Every input is different, and processed separately, with no knowledge of what was processed before.
In such networks, sequenced data is generally arranged back-to-back as a single vector, and fed into the network. Such networks are called feedforward networks.
While this works for structured/tabular data, it does not work too well for sequenced, or temporal data (eg, a time series, or a sentence, where words follow each other in a sequence).
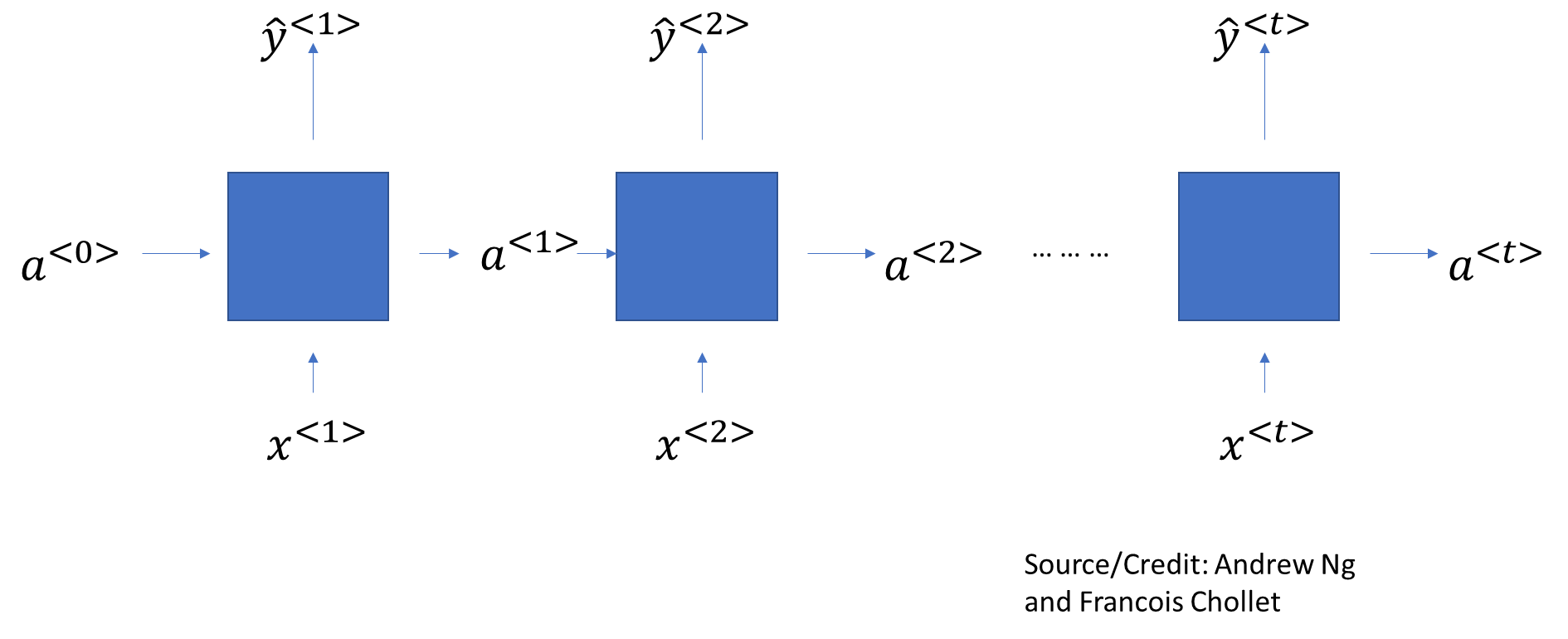
Recurrent Neural Networks try to solve for this problem by maintaining a memory, or state, of what it has seen so far. The memory carries from cell to cell, gradually diminishing over time.
A SimpleRNN cell processes batches of sequences. It takes an input of shape (batch_size, timesteps, input_features).
image.png
How the network calculates is:
image.png
So for each element of the sequence, it calculates an \(a\), and then it also calculates the output $ $ as a function of both \(a\) and \(x\). State information from previous steps is carried forward in the form of a.
However SimpleRNNs suffer from the problem of exploding or vanishing gradients, and they don’t carry forward information into subsequent cells as well as they should.
In practice, we use LSTM and GRU layers, which are also recurrent layers.
RNNs vs Transformers for sequences: LSTMs and GRUs were state-of-the-art for sequence tasks until 2018. Today, transformer-based models (BERT, GPT) outperform RNNs on virtually every NLP benchmark because attention is computed across all positions in parallel — no sequential bottleneck. RNNs still appear in resource-constrained settings (microcontrollers, real-time streaming) where transformers’ quadratic memory cost is prohibitive. For time series forecasting specifically, hybrid architectures like Temporal Fusion Transformer (TFT) and N-BEATS now lead benchmarks.
The GRU Layer
GRU = Gated Recurrent Unit The purpose of GRU is to retain memory of older layers, and persist old data in subsequent layers. In GRU, an additional ‘memory cell’ \(c^{<t>}\) is also output that is carried forward.
The way it works is: find a ‘candidate value’ for \(c^{<t>}\) called \(\hat{c}^{<t>}\). Then find a ‘gate’, which is a 0 or 1 value, to decide whether to carry forward the \(c^{<t>}\) value from the prior layer, or update it.
image.png
where - \(G_u\) is the UPDATE GATE,
- \(G_f\) is the RESET GATE,
- \(W\) are the various weight vectors, \(b\) are the biases
- \(x\) are the inputs, \(a\) are the activations
- \(tanh\) is the activation function
Source/Credit: Andrew Ng
The LSTM Layer
LSTM = Long Short Term Memory
LSTM is a generalization of GRU. The way it differs from a GRU is that in GRUs, \(c ^ {<t>}\) and \(a^{<t>}\) are the same, but in an LSTM they are different.
image.png
where
- \(G_u\) is the UPDATE GATE,
- \(G_f\) is the FORGET GATE,
- \(G_o\) is the OUTPUT GATE
- \(W\) are the various weight vectors, \(b\) are the biases
- \(x\) are the inputs, \(a\) are the activations
- \(tanh\) is the activation function
Finally…
Deep Learning is a rapidly evolving field, and most state-of-the-art modeling tends to be fairly complex than the simple models explained in this brief class.
Network architectures are difficult to optimize, there is no easy answer to the question of the number and types of layers, their size and order in which they are arranged.
Data scientists spend a lot of time optimizing architecture and hyperparameters.
Network architectures can be made arbitrarily complex. While we only looked at ‘sequential’ models, models that accept multiple inputs, split processing in the network, and produce multiple outcomes are common.
Where deep learning stands today (2024–2025)
Architecture
Dominant use
Dense / MLP
Tabular data, simple regression
CNN
Image classification, object detection
RNN / LSTM / GRU
Time series on constrained hardware
Transformer (encoder)
Text classification, NER (BERT family)
Transformer (decoder)
Text generation, code (GPT family)
Multimodal (CLIP, ViT+LM)
Image-text tasks, visual QA
Diffusion models
Image/audio/video generation
Practical starting points: - Fine-tune a pre-trained model from Hugging Face (transformers library) rather than training from scratch — this requires far less data and compute for most tasks. - Use PyTorch Lightning or Keras to avoid boilerplate training loops. - Track experiments with Weights & Biases (wandb) or MLflow. - For deployment at scale, ONNX runtime or TensorFlow Lite can compress and speed up inference.
18.10 END
STOP HERE ***
18.11 Example of the same model built using the Keras Functional API